Herramientas de Scraping de Datos Instantáneo: Formas Rápidas para Extraer Datos de la Web Sin Código

Rajinder Singh
Deep Learning Researcher
TL;Dr: Puntos clave
- Las herramientas Instant Data Scraper permiten a los usuarios recopilar datos estructurados de sitios web en segundos sin necesidad de escribir ningún código.
- Las extensiones de navegador como Instant Data Scraper son ideales para tareas simples y puntuales, mientras que las soluciones basadas en API ofrecen mejor escalabilidad.
- Las herramientas modernas utilizan IA para detectar automáticamente tablas y listas, reduciendo significativamente el tiempo necesario para la preparación de datos.
- Para sitios web complejos con medidas de seguridad, integrar un solucionador especializado como CapSolver garantiza un flujo de datos ininterrumpido.
- Elegir la herramienta adecuada depende de sus necesidades específicas en cuanto al volumen, frecuencia y complejidad técnica del sitio objetivo.
El scraping de web ha evolucionado de una tarea compleja de programación a un proceso optimizado accesible para todos. Hoy en día, las herramientas Instant Data Scraper permiten a los mercadólogos, investigadores y propietarios de negocios recopilar información valiosa de la web con solo unos pocos clics. Estas herramientas eliminan la necesidad de scripts en Python o configuraciones complejas, haciendo que la extracción de datos sea tan simple como navegar por una página web. Ya sea que esté buscando monitorear precios de competidores o construir una lista de generación de clientes, la herramienta adecuada puede ahorrarle cientos de horas de trabajo manual. Esta guía explora las formas más eficientes de extraer datos web sin código, ayudándole a elegir la mejor solución para su estrategia de datos de 2026.
Entendiendo las herramientas Instant Data Scraper
El término herramientas Instant Data Scraper se refiere a una categoría de software diseñado para la recolección inmediata de datos de páginas web. A diferencia de los scrapers tradicionales que requieren mapeo manual de selectores, estas herramientas utilizan algoritmos heurísticos o IA para identificar patrones en estructuras HTML. Esto significa que pueden reconocer listas de productos, feeds de noticias o resultados de búsqueda de forma automática. El volumen global de datos creados y consumidos está creciendo exponencialmente, lo que hace que las herramientas de extracción rápida sean más críticas que nunca.
La mayoría de las herramientas Instant Data Scraper operan como extensiones de navegador o APIs basadas en la nube. Las extensiones son perfectas para tareas rápidas donde solo necesita datos de la página que está viendo actualmente. Las herramientas basadas en la nube, por otro lado, son más adecuadas para operaciones a gran escala donde necesita extraer miles de URLs simultáneamente. Comprender estas diferencias es el primer paso para optimizar su flujo de trabajo de recolección de datos.
Mejores herramientas Instant Data Scraper en 2026
El mercado de extracción sin código ha madurado significativamente, con varios destacados líderes. Cada herramienta ofrece características únicas adaptadas a diferentes requisitos de usuarios. A continuación se presenta una comparación de las herramientas Instant Data Scraper más valoradas disponibles actualmente.
Resumen de comparación: Mejores extractores de datos web
| Nombre de la herramienta | Tipo | Ideal para | Facilidad de uso | Escalabilidad |
|---|---|---|---|---|
| Instant Data Scraper | Extensión de Chrome | Extracción rápida de tablas | Alta | Baja |
| ScraperAPI | API en la nube | Pipelines automatizadas de alto volumen | Media | Alta |
| Octoparse | Aplicación de escritorio | Sitios web complejos con paginación | Media | Media |
| WebScraper.io | Extensión | Contenido dinámico y mapas del sitio | Media | Media |
| Data Miner | Extensión | Recetas predefinidas para sitios populares | Alta | Media |
1. Instant Data Scraper (Extensión de Chrome)
Esta es posiblemente la elección más popular para principiantes. Es una extensión de navegador gratuita que utiliza IA para predecir qué datos son más relevantes en una página. Al hacer clic en el icono de la extensión, inmediatamente resalta la tabla o lista detectada y muestra una vista previa de los datos. Es una de las formas más efectivas de extraer datos web rápidamente sin código porque no requiere configuración alguna.
La herramienta admite desplazamiento infinito y botones "Localizar siguiente" para la paginación. Esto le permite extraer múltiples páginas de resultados de búsqueda sin intervención manual. Sin embargo, debido a que funciona localmente en su navegador, no es adecuada para extraer millones de páginas o manejar protecciones antiscraping intensas. Para quienes busquen opciones más robustas, revisar las mejores herramientas de extracción de datos puede proporcionar una perspectiva más amplia sobre soluciones empresariales.
2. DataPipeline de ScraperAPI
Para usuarios que necesitan más que solo una extensión de navegador, ScraperAPI ofrece una solución de bajo código llamada DataPipeline. Esta herramienta le permite cargar una lista de URLs y recibir datos estructurados en formato JSON o CSV a cambio. Maneja automáticamente todas las barreras técnicas como la rotación de IPs y la gestión de encabezados.
Una de las ventajas clave de utilizar herramientas Instant Data Scraper basadas en API es la capacidad de evitar restricciones comunes. Muchos sitios web utilizan métodos sofisticados para identificar y bloquear el tráfico automatizado. Al usar un servicio que sabe cómo evitar los bloqueos de IP, puede garantizar que su recolección de datos permanezca constante y confiable.
Superando los desafíos en el scraping instantáneo
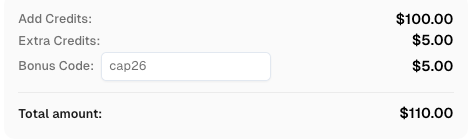
Use el código
CAP26al registrarse en CapSolver para recibir créditos adicionales!
Aunque las herramientas Instant Data Scraper son increíblemente poderosas, a menudo enfrentan obstáculos en sitios web modernos. Medidas de seguridad como CAPTCHAs y sistemas de detección de bots están diseñadas para prevenir el acceso automatizado. Esto es donde un scraper estándar podría fallar, dejándole con datos incompletos o una dirección IP bloqueada.
Para mantener un proceso de extracción sin interrupciones, muchos profesionales integran sus scrapers con servicios especializados. Por ejemplo, CapSolver proporciona una capa esencial de soporte al manejar desafíos de verificación complejos. Al usar un solucionador confiable, puede garantizar que sus herramientas Instant Data Scraper puedan acceder incluso a los sitios web más protegidos sin ser marcados como bots. Esto es especialmente importante al lidiar con los prompts "No soy un bot" que frecuentemente aparecen durante el scraping de alta frecuencia.
Características esenciales a buscar
Al evaluar herramientas Instant Data Scraper, debe priorizar características que se alineen con sus objetivos a largo plazo. Una herramienta que funcione hoy podría no ser suficiente a medida que sus necesidades de datos crezcan. Considere los siguientes criterios:
- Reconocimiento automático de patrones: La herramienta debe identificar listas y tablas sin entrada manual de selectores.
- Soporte de paginación: Capacidad para manejar botones "Cargar más", desplazamiento infinito y páginas numeradas.
- Opciones de exportación: Soporte para formatos CSV, Excel y JSON para una integración sencilla con otros software.
- Ejecución en la nube: La opción de ejecutar tareas de scraping en un servidor en lugar de en su máquina local.
- Integración con anti-detección: Compatibilidad con proxies y solucionadores de CAPTCHA para mantener altas tasas de éxito.
Cómo usar un Instant Data Scraper: Guía paso a paso
Usar herramientas Instant Data Scraper es generalmente sencillo. La mayoría de las herramientas siguen un flujo de trabajo similar que prioriza velocidad y simplicidad. Así es como puede comenzar a extraer datos en minutos:
- Instale la herramienta: Descargue la extensión desde la Chrome Web Store o regístrese para un servicio basado en la nube.
- Navegue al sitio objetivo: Abra la página web que contiene los datos que desea extraer, como una página de categoría de comercio electrónico.
- Active el escaper: Haga clic en el icono de la herramienta. La IA resaltará el área de datos detectada.
- Refine la selección: Si la herramienta omite una columna, generalmente puede hacer clic para agregarla manualmente.
- Maneje la paginación: Si los datos abarcan múltiples páginas, use la función "Localizar siguiente" para guiar al escaper.
- Descargue sus datos: Una vez completada la extracción, exporte los resultados a su formato preferido.
Para usuarios más avanzados, seguir el Estándar WebDriver de W3C puede ayudar a entender cómo interactúan estas herramientas con entornos de navegador a un nivel más profundo.
El papel de la IA en la extracción de datos moderna
La nueva generación de herramientas Instant Data Scraper está profundamente influenciada por la Inteligencia Artificial. La IA permite que estas herramientas entiendan el contexto de una página en lugar de solo su código. Por ejemplo, un escaper impulsado por IA puede distinguir entre un precio de producto y un precio descuento, incluso si las etiquetas HTML son similares.
Este cambio hacia la extracción inteligente está haciendo que las herramientas de scraping sin código 2026 sean más confiables que nunca. A medida que los sitios web se vuelven más dinámicos y complejos, la capacidad de una herramienta para adaptarse a cambios en el diseño sin intervención del usuario es una gran ventaja competitiva. Por eso, muchas empresas están dejando atrás scrapers rígidos basados en selectores para optar por soluciones más flexibles y rápidas.
Conclusión
El auge de las herramientas Instant Data Scraper ha democratizado el acceso a datos web, permitiendo a cualquiera convertirse en un tomador de decisiones basado en datos. Al elegir la herramienta adecuada -ya sea una extensión simple para tareas rápidas o una API robusta para proyectos a gran escala- puede acelerar significativamente su investigación y operaciones. Recuerde que las estrategias de scraping más exitosas a menudo involucran una combinación de formas rápidas de extraer datos web sin código y servicios especializados como CapSolver para manejar desafíos de seguridad. Al construir su canal de datos, enfóquese en escalabilidad y confiabilidad para garantizar que sus insights permanezcan precisos y oportunos.
Preguntas frecuentes
1. ¿Son legales las herramientas Instant Data Scraper?
Sí, el scraping de web es generalmente legal para datos disponibles públicamente. Sin embargo, siempre debe respetar el archivo robots.txt de un sitio web y sus términos de servicio. Para más detalles, debe consultar recursos legales sobre ética de recolección de datos y regulaciones regionales.
2. ¿Puedo extraer sitios web que requieren inicio de sesión?
Algunas extensiones de web scraper para Chrome pueden manejar sesiones iniciadas porque utilizan las cookies de su navegador. Sin embargo, los scrapers basados en la nube generalmente requieren configuraciones más complejas para manejar la autenticación.
3. ¿Cuál es la diferencia entre una extensión de navegador y una API de scraping web?
Una extensión funciona en su navegador y es ideal para tareas pequeñas. Una API funciona en un servidor remoto, permitiendo un volumen mucho mayor y mejores capacidades de automatización.
4. ¿Cómo manejo los CAPTCHAs durante el scraping?
La forma más efectiva es usar un servicio dedicado como CapSolver. Se integra con su extracción automatizada de datos para resolver desafíos en tiempo real, asegurando que su escaper nunca se quede bloqueado.
5. ¿Necito conocer HTML para usar estas herramientas?
Aunque el conocimiento básico de la estructura HTML es útil, la mayoría de los scrapers instantáneos están diseñados para funcionar sin ningún conocimiento técnico. Para quienes estén interesados en la tecnología subyacente, la Especificación de Tablas HTML de W3C proporciona una profundización en la organización de datos en la web.
Ver más
web scrapingApr 22, 2026
Arquitectura de raspado de web para extracción de datos escalable
Aprende una arquitectura de raspado web escalable en Rust con reqwest, scraper, raspado asíncrono, raspado con navegador sin cabeza, rotación de proxies y manejo de CAPTCHA conforme.

web scrapingFeb 17, 2026
Cómo resolver Captcha en Nanobot con CapSolver
Automatiza la resolución de CAPTCHA con Nanobot y CapSolver. Utiliza Playwright para resolver reCAPTCHA y Cloudflare autónomamente.


